
Son yıllarda sayısal ortamlarda saklanan veri miktarının hızla artması ve bu verilerin nitelikli bilgiye, karar verme süreci içerisine dahil edilmesi istenmesi sonucu bazı alanların oluşmasına neden olmuştur. 2012 rakamları ile dünyada günlük 2.5 Kentirilyon byte veri üretilmektedir.
Büyük veri tabanları içerisinde daha önceden bilinmeyen, nitelikli bilgilerin(knowledge) ortaya çıkarılabilmesi için kullanılan İstatistik (Statistic), Makine Öğrenmesi (Machine Learning), Yapay Zeka(Artificial Intelligence), Veritabanı Yönetimi(Database Management) ve Veri Görselleştirme (Data Visualization)vd. yöntemleri içeren teknikler bütünüdür. Nitelikli bilgi örüntü (pattern), birliktelik kuralları(association rules) olarak ortaya çıkmaktadır. Veri Madenciliği süreci Veri Tabanı Bilgi Keşfi (Knowledge Discovery in Databases) kısaca VTBK (KDD) olarak isimlendiren sürecin bir adımı olarak ifade edilebilir.

Gartner Group sitesinde yer alan açıklama da;
“The process of discovering meaningful correlations, patterns and trends by sifting through large amounts of data stored in repositories. Data mining employs pattern recognition technologies, as well as statistical and mathematical techniques.”
Veri Madenciliği, istatistiksel ve matematiksel yöntemlerle birlikte örüntü tanıma teknolojilerini kullanarak, depolanan veri yığınları arasında anlamlı yeni ilişki, örüntü ve eğilimlerin keşfedilmesi süreci olarak ifade edilmektedir.
Veri madenciliği mevcut veriden anlamlı bilgileri, ilişkileri çıkarmada kullanılan tekniklere verilen genel isimdir.
Veri Madenciliği,
- Makine öğrenimi & Yapay zeka,
- İstatistik,
- Veri tabanları,
- Uzman sistemler,
- Veri görselleştirme gibi disiplinlerini içeren yöntem topluluğudur.
Kısaca ifade edecek olursak “Veriyi Nitelikli Bilgiye Dönüştürme Yolu” olarak tanımlayabiliriz.
Enformasyon(Information) vs Bilgi(Knowledge)

Enformasyon; elinizde bulunan veriler birer enformasyondur ve statiktir.
Bilgi; Bu verilere değer katılması, sonuca varılması olarak ifade edilebilir ve dinamiktir.
Bir olay üzerinden ifade edecek olursak;
Veri(Data), 31 Aralık 2014 tarihi itibariyle Türkiye nüfusu 77 milyon 695 bin 904 kişidir.
Enformasyon(Information), Türkiye’de yıllara bağlı olarak;
Nüfus Artış Hızı ‰13.3,
Cinsiyet Dağılımı Kadın 38.711.602, Erkek 38.984.302 kişi,
İl ve ilçe Merkezleri Nüfus 71.286.182, Köy ve Belde Nüfus 6.409.722
Ortanca Yaşın 30,7 vb. nitelikler ile ifade edilebilir.
Bilgi(Knowledge) ise Türkiye nüfus artış hızının 2013 (Nüfus Artış Hızı ‰13.7) yılına göre azaldığı, nedenlerinin ortaya çıkarılması, sosyal durumlar ile ilişkilerinin saptanması. Aynı şekilde Ortanca yaşın 2013 (Ortanca Yaş 30,4) yılına göre artmasının Nüfus Artış Hızının azalması ile ilgili olduğunun saptanması olarak ifade edilebilir.
Veri Madenciliğinin Tarihsel Keşfi & Gelişimi

- 1950’ler İlk bilgisayarlar (Sayımlar için bilgisayarlar kullanılıyor)
- 1960’lar Veri koleksiyonları Veritabanı yaratımı (Hiyerarşik ve ağ modelleri)
- 1970’ler İlişkisel veri modeli İlişkisel VTYS uygulamaları
- 1980’ler İlişkisel VTYS yaygınlaşı Uygulamaya yönelik VTYS (Mekansal, Bilimsel, Mühendislik, vs.)
- 1990’lar; Günlük işlemlerden derlenen büyük miktarda verinin nasıl değerlendirilebileceği sorgulanmaya başlıyor:
- 1989, VTBK (KDD-IJCAI)-89 Veri Tabanlarında Bilgi Keşfi Çalışma Grubu toplantısı
- 1991, VTBK (KDD-IJCAI)-89’un sonuç bildirgesi sayılabilecek ‘Knowledge Discovery in Real Databases: A Report on the IJCAI-89 Workshop’ makalenin KDD ile ilgili temel tanım ve kavramları ortaya koyması
- 1992, Veri Madenciliği konusunda ilk yazılımın geliştirilmesi
- 1995, Uluslararası Bilgi Keşfi ve Veri Madenciliği Konferansı’nın (KDD-95) açılış konuşması
- 2000’ler; Veri Ambarları, Veri Madenciliği yaygınlaşı
Veri Madenciliği Süreçleri (Data Mining Techniques)
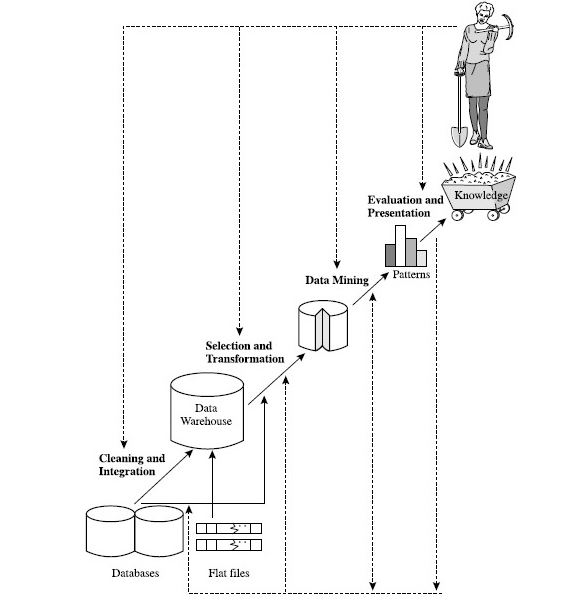
Bir veri madenciliği sürecinin %60 ile %80’lik kısmı veri hazırlama safhası oluşturmaktadır. Veri kaynaklarının belirlenmesi, veri ambarlarının oluşturulması, veri marketlerinin oluşturulması vs. durumların olduğunun bilinmesi gerekmektedir. Elinizdeki kaynak ne kadar doğru ve güvenilir ise elde edeceğiniz sonuçların güvenilirliği yüksek olacaktır.
Veri madenciliğini süreci aşağıda belirtilen adımları içermektedir.
- Veri Temizleme,
- Veri Bütünleştirme,
- Veri Seçme (İndirgeme),
- Veri Dönüştürme,
- Veri Madenciliği Algoritmaları Uygulanması,
- Örüntüler (Desenler)
- Sunum ve Değerlendirme
Veri Madenciliği Metodolojileri (Data Mining Methodologies)
Veri madenciliği sürecinde kullanılan metodolojiler aşağıda belirtilmiştir. CRISP-DM ve SEMMA metodolojilerinin dışında şirketlere özel metodolojilerde bulunmaktadır. Metodolojiler veri madenciliği sürecinin nasıl yapılması gerektiği ifade etmektedir.
1.CRISP-DM (Cross Industry Standard Process for Data Mining)
2.SEMMA (Sample,Explore, Modify, Model and Assess)

Veri Madenciliği Modelleri (Data Mining Models)
A. Tahmin Edici Modeller (Predictive) / Tanımlayıcı Modeller (Descriptive)
1.Tahmin Edici Modeller (Predictive)
a. Sınıflandırma
b. Regresyon
c. Zaman Serisi Analizi
2.Tanımlayıcı Modeller (Descriptive)
a. Kümeleme
b. Birliktelik Kuralları
B. Denetimli (Supervised)/ Denetimsiz Modeller (Unsupervised)
| Denetimli(Supervised) | Denetimsiz(Unsupervised) | ||
| Tahmin (Prediction) | Sınıflandırma (Classification) | * | |
| Regresyon (Regression) | * | ||
| Birliktelik (Association) | Bağlantı Analizi (Link Analysis) | * | |
| Ardışık Zamanlı (Sequence Analysis) | * | ||
| * | |||
| Kümeleme (Clustering) | Aykırı Değer Analizi (Outlier Analysis) | * |
Veri Madenciliği Yöntemleri (Data Mining Techniques)
1. Birliktelik Kuralları (Association Rules)
Olayların birlikte gerçekleşme durumlarını çözümleyen veri madenciliği yöntemlerine birliktelik kuralları denir. Bu yöntemler, birlikte olma kurallarını belirli olasılıklarla ortaya koyar. Birliktelik kuralı, geçmiş verilerin analiz edilerek bu veriler içindeki birliktelik davranışlarının tespiti ile geleceğe yönelik çalışmalar yapılmasını destekleyen bir yaklaşımdır.
Birliktelik kuralları algoritmalarından bazıları; Apriori, Carma, Sequence, Gri.
2.Sınıflandırma ve Tahmin (Classification and Predicton)

Veri içindeki gizli örüntülerin ortaya çıkarılması amacıyla sınıflandırma modelleri kullanılır. Sınıflandırmanın kümelemeden farkı veri içerisinde sınıflar belirlidir. Sınıfların yeniden oluşturulması söz konusu olamaz. Danışmalı öğrenme (supervised) yöntemleri içerisinde yer almaktadır.
Sınıflandırma Algoritmalarından bazıları; Karar Ağaçları, Yapay Sinir Ağları, Genetik Algoritmalar, K-en Yakın Komşu, Bayes Ağları, Destek Vektör Makinaları, Lojistik Regresyon.
3.Kümeleme Analizi (Cluster Analysis)

Nesnelerin birbirleri arasında belirli ilişkiler kurularak alt gruplara ayrılması işlemine kümeleme denir. Kümeleme işlemi yapılırken gruplar arası fark maksimum olurken grup içi farklılık minimum olması sağlanır. Böylece her grup birbirinden farklı ancak grup içi nesneler birbirine benzer olacak şekilde bölme işlemi gerçekleşmiş olur. Danışmasız öğrenme (unsupervised) yöntemleri içerisinde yer almaktadır.
Kümeleme algoritmalarından bazıları; Hiyerarşik Algoritmalar, Hiyerarşik Olmayan Algoritmalar.
Uygulama Alanları
Veri madenciliği günümüzde yaygın bir kullanım alanı bulunmaktadır. Bunlardan bazıları aşağıda verilmiştir.
- Müşteri İlişkileri Yönetimi
- Pazarlama kampanyalarında getirinin maksimizasyonu,
- Müşteri sadakatinin artırılması (churn analizi),
- Müşteri değerinin artırılması(cross- ya da up-selling).
- Pazarlama
- Pazar sepeti analizi (Market Basket Analysis),
- Müşteri değerlendirme (Customer Value Analysis),
- Müşteri ilişkileri yönetimi (Customer Relationship Management),
- Satış tahmini (Sales Forecasting).
- Bankacılık & Finans Sektörü
- Kredi taleplerinin değerlendirilmesi,
- Sahtekârlık işlemlerinin tespiti (fraud analizi).
- Sigortacılık
- Riskli müşteri gruplarının belirlenmesi,
- Sigorta dolandırıcılığı tespiti,
- Yeni poliçe satın alabilecek müşterilerin tespiti.
- Mühendislik ve Fen Bilimlerinde,
- Savunma Sanayiinde,
- Ulusal ve Uluslararası Güvenlikte,
- Ulaştırma & Lojistik Endüstrisinde,
- Sağlık & İlaç Sektöründe,
- Spor Bilimlerinde.
| Ticari Yazılımlar | Ticari Olmayan Yazılımlar |
|
|
|
|
|
|
|
|
|
Görüş, öneri ve katkıda bulunmak ve beraber öğrenmek isterseniz uslumetin@gmail.com ‘dan bana ulaşabilirsiniz.
Not: Bu yazı ilk kez 5 Ekim 2015 tarihinde Kod5.org sitesinde yayınlanmıştır.
Kaynaklar ve Dipnotlar
-
İstatistik; veri toplama, tablo ve grafiklerle özetleme, sonuçları yorumlama, sonuçların güven derecelerini açıklama, örneklerden elde edilen sonuçları kitle için genelleme, özellikler arasındaki ilişkiyi araştırma, çeşitli konularda geleceğe ilişkin tahmin yapma, deney düzenleme ve gözlem ilkelerini kapsayan bir bilimdir. https://tr.wikipedia.org/wiki/%C4%B0statistik
-
Makine Öğrenmesi; verilen bir problemi probleme ait ortamdan edinilen veriye göre modelleyen bilgisayar algoritmalarının genel adıdır. http://bmb.cu.edu.tr/uorhan/DersNotu/Ders01.pdf
-
Yapay Zeka; makinelere insanlar gibi düşünme, karar verme, karşılaştırma, analiz etme gibi birtakım fonksiyonların kazandırılmasıdır. Fikir babası ‘Makineler Düşünebilir mi?’ sorunsalı ortaya atan Allan Mathison Turing’dir.
-
Veritabanı Yönetimi; veri tabanlarını tanımlamak, yaratmak, kullanmak, değiştirmek ve veri tabanı sistemleri ile ilgili her türlü işletimsel gereksinimleri karşılamak için tasarlanmış sistem ve yazılımdır. https://tr.wikipedia.org/wiki/Veritaban%C4%B1_y%C3%B6netim_sistemi
-
Veri Görselleştirme; popüler enformatik tekniği olan veri görselleştirme yapısal ve yapısal olmayan veri kütlesi etkileyici çarpıcı şekilde ortaya sunulması olarak ifade edilebilir.http://www.slideshare.net/FatmaINAR/visual-analysis-43729548
Örüntü; sürekli devam ve tekrar eden yapılar olarak açıklanmaktadır.
-
Birliktelik Kuralları; geçmiş verilerin analiz edilerek bu veriler içindeki birliktelik davranışlarının tespiti ile geleceğe yönelik çalışmalar yapılmasını destekleyen bir yaklaşımdır. http://www.wideskills.com/data-mining-tutorial/data-mining-techniques
-
ADNKS 2014 Haber Bülteni, http://www.tuik.gov.tr/PreHaberBultenleri.do?id=18616 2014
-
ADNKS 2013 Haber Bülteni, http://www.tuik.gov.tr/PreHaberBultenleri.do?id=15974 2013
-
Data Mining Consept and Techniques, Jiawei Han and Micheline Kamber, Morgan Kaufmann Publishers
-
http://timkienthuc.blogspot.com.tr/2012/04/crm-and-data-mining-day-08.html